Improving Compute Efficacy Frontiers with SliceOut
Abstract
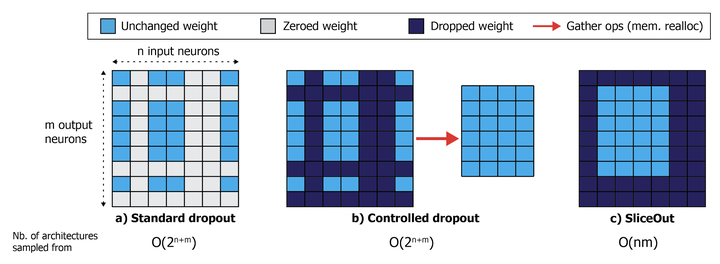
Pushing forward the compute efficacy frontier in deep learning is critical for tasks that require frequent model re-training or workloads that entail training a large number of models. We introduce SliceOut – a dropout-inspired scheme designed to take advantage of GPU memory layout to train deep learning models faster without impacting final test accuracy. By dropping contiguous sets of units at random, our method realises training speedups through (1) fast memory access and matrix multiplication of smaller tensors, and (2) memory savings by avoiding allocating memory to zero units in weight gradients and activations. At test time, turning off SliceOut performs an implicit ensembling across a linear number of architectures that preserves test accuracy. We demonstrate 10-40% speedups and memory reduction with Wide ResNets, EfficientNets, and Transformer models, with minimal to no loss in accuracy. This leads to faster processing of large computational workloads overall, and significantly reduce the resulting energy consumption and CO2 emissions.