Protriever: End-to-End Differentiable Protein Homology Search for Fitness Prediction
 Protriever
Protriever
Abstract
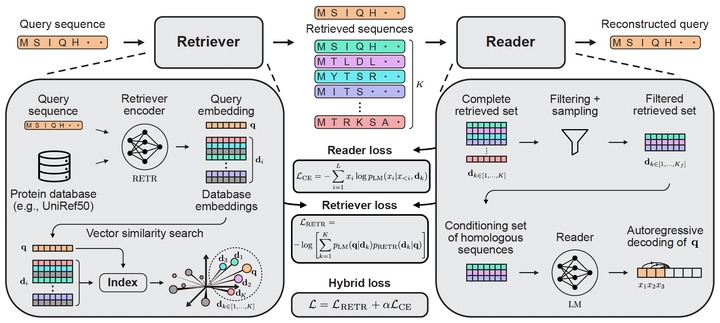
Retrieving homologous protein sequences is essential for a broad range of protein modeling tasks such as fitness prediction, protein design, structure modeling, and protein-protein interactions. Traditional workflows have relied on a two-step process: first retrieving homologs via Multiple Sequence Alignments (MSA), then training models on one or more of these alignments. However, MSA-based retrieval is computationally expensive, struggles with highly divergent sequences or complex insertions & deletions patterns, and operates independently of the downstream modeling objective. We introduce Protriever, an end-to-end differentiable framework that learns to retrieve relevant homologs while simultaneously training for the target task. When applied to protein fitness prediction, Protriever achieves state-of-the-art performance compared to sequence-based models that rely on MSA-based homolog retrieval, while being two orders of magnitude faster through efficient vector search. Protriever is both architecture- and task-agnostic, and can flexibly adapt to different retrieval strategies and protein databases at inference time – offering a scalable alternative to alignment-centric approaches.